

奧里希·勞森 |蓋蒂圖片社
週二,谷歌和特拉維夫大學的研究人員推出了 GameNGen,這是一種新的 AI 模型,可以互動模擬 1993 年經典的第一人稱射擊遊戲 厄運 使用借用穩定擴散的人工智慧影像產生技術即時產生。它是一個神經網路系統,可以充當有限的遊戲引擎,有可能為未來的即時視訊遊戲合成開闢新的可能性。
例如,未來的遊戲可能不使用傳統技術繪製圖形視訊幀,而是使用人工智慧引擎來即時「想像」或產生幻覺圖形作為預測任務。
」應用程式開發人員 Nick Dobos 在回應這一消息時寫道:“這裡的潛力是荒謬的。當人工智慧可以為你思考每個像素時,為什麼要手動為軟體編寫複雜的規則呢?”
據報道 GameNGen 可以產生新的幀 厄運 使用單一張量處理單元 (TPU) 以每秒超過 20 幀的速度進行遊戲,TPU 是一種類似於 GPU 的專用處理器,針對機器學習任務進行了最佳化。
研究人員表示,在測試中,10 名人類評分者有時無法區分實際的短片(1.6 秒和 3.2 秒)。 厄運 GameNGen 產生的遊戲鏡頭和輸出,可在 58% 或 60% 的時間內識別真實的遊戲鏡頭。
GameNGen 的實際範例,使用圖像合成模型互動模擬 Doom。
使用所謂的「神經渲染」進行即時視訊遊戲合成並不是一個全新的想法。 Nvidia 執行長黃仁勳在 3 月的一次採訪中預測,也許有些大膽,大多數電玩遊戲圖形可以在五到 10 年內由人工智慧即時生成。
GameNGen 也建立在 GameNGen 論文中引用的該領域之前的工作基礎上,其中包括 2018 年的 World Models、2020 年的 GameGAN 以及 3 月份谷歌自己的 Genie。今年早些時候,一組大學研究人員使用擴散模型訓練了一個人工智慧模型(稱為「DIAMOND」)來模擬老式 Atari 電玩遊戲。
此外,正在進行的「世界模型」或「世界模擬器」研究通常與 AI 視訊合成模型(如 Runway 的 Gen-3 Alpha 和 OpenAI 的 Sora)相關,也傾向於類似的方向。例如,在Sora首次亮相期間,OpenAI展示了AI生成器模擬的演示視頻 我的世界。
擴散是關鍵
在一篇題為「擴散模型是即時遊戲引擎」的預印本研究論文中,作者 Dani Valevski、Yaniv Leviathan、Moab Arar 和 Shlomi Fruchter 解釋了 GameNGen 的工作原理。他們的系統使用 Stable Diffusion 1.4 的修改版本,這是 2022 年發布的圖像合成擴散模型,人們用它來產生人工智慧生成的圖像。
「結果是『它能跑嗎? 厄運?對於擴散模型來說是肯定的,」穩定性人工智慧研究總監 Tanishq Mathew Abraham 寫道,他沒有參與該研究計畫。
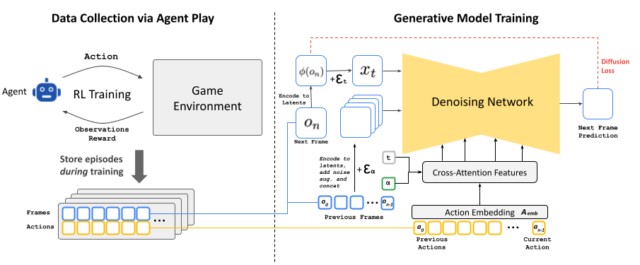
在受玩家輸入指導的同時,擴散模型在經過大量的視訊片段訓練後,可以根據先前的遊戲狀態預測下一個遊戲狀態。 厄運 在行動中。
GameNGen 的發展涉及兩個階段的訓練過程。最初,研究人員訓練了一個強化學習代理來玩 厄運,記錄遊戲過程以創建自動生成的訓練資料集——我們提到的那個鏡頭。然後他們使用這些數據來訓練客製化的穩定擴散模型。
然而,使用穩定擴散會引入一些圖形故障,正如研究人員在摘要中指出的那樣:「穩定擴散 v1.4 的預訓練自動編碼器將 8×8 像素區塊壓縮為 4 個潛在通道,當預測遊戲幀,這會影響小細節,尤其是底欄HUD。
GameNGen 的實際範例,使用圖像合成模型互動模擬 Doom。
這並不是唯一的挑戰。隨著時間的推移保持影像視覺上清晰和一致(在人工智慧影片領域通常稱為「時間一致性」)可能是一個挑戰。 GameNGen 研究人員在論文中寫道,「互動式世界模擬不僅僅是非常快速的視訊生成」。 “對僅在整個生成過程中可用的輸入動作流進行條件的要求打破了現有擴散模型架構的一些假設”,包括根據先前的幀重複生成新幀(稱為“自回歸”),這可能會導致不穩定和隨著時間的推移,生成世界的品質迅速下降。

:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/25632897/2172275494.jpg?w=768&resize=768,0&ssl=1 "紐約自由人隊在 WNBA 季後賽中對陣亞特蘭大夢想隊:預覽、預測、賽程、對決等")


